







人不光是靠两只眼睛完成“空间感”的,用一只眼睛从不同角度也可以,甚至不用眼睛而用其他感观也可以。一定要结合触觉和行动对环境的认知,视觉只是与之配合的一种手段。没眼睛一样有空间感。很多盲人比我们定位更准确。
三维环境不用预定义,但至少三维“空间”还是要定义的。如果所谓的强AI中没有空间的概念,没有虚拟的“想象”空间,甚至不会运动,那么,它连最基本的“前,后,左,右”都无法理解。现在在你面前,你认为你看到了空间还是图片?大脑有空间想象力。怎么定义“前”、“后”,与你的空间想象有关,也与你实际的运动经验有关。
我们怎么定义苹果?只是文字描述吗?建立在符号逻辑中的AI没有现实意义。人脑处理的本来就不是符号信息,建立在符号逻辑中的AI没有现实意义。人是靠形象思维的,而概念是对形象思维的抽象。离开了前提直接讨论抽像的符号,能真正“理解”吗?
你心里的苹果是什么?你所“想象”的AI又该怎么认为“苹果”?圆的,红的或绿的,能吃?它会吃么?它知道什么才是圆的?是圆圈还是圆球?无论强AI还是机器认知,想模仿人的话,先从形象思维开始,先从构建3D空间开始。抽象的概念等有了观察的“感性认识”才有意义。
人最先学会的基本都是名词,都是观察的事物和接触到的事物,而且是与自己相关的。第一个动词是“不要”,而后是各种与“名词”表示的具体事物相关的动词。会说“我”这样的代词已经是四五岁以后的事了,这时候才有了自我意识。没有观察,没有形象认知到概念抽象的过程,没有事物与自身关系的感觉,怎么能形成“人类”的意识。
在行动,和认识的经验前提下,三维“感”(也包括立体感),可以从二维图像得到。设想一下,如果从没运动地接触或观察(从多角度接触或观察)过任何事物,那么给你一个单一角度的照片,或只让你从一个角度去看事物及环境能否行成“三维”概念?我认为不能。因为三维是从多角度观察,以及自身的运动与环境的关系,得出的感性体验与认识,你看到事物知道是三维,因为你有过这样的经验。
人类从儿童时期起就是在不断的运动中感知和观察事物。从咬、拿、踩、踢、看、撞等引起的交互感知中来认识环境。这与视觉(或没眼睛靠其他方式)得出的“观察”相结合,产生出“空间感”。
描述一件事物,3维够吗?颜色、温度、硬度、味道、用途、类别,每种你能“类别化”的属性。都可以算作一个维度。从这个意义上讲是无限维。而“三维”只是我们描述空间形态与位置关系的基本手段,远不足以描述“识知”的事物。
脱离形象思维单纯谈认知,至少不符合人类的智能模式,这是关系到实用与实现的问题。AI不一定非照搬人类的模式,但这是最实用的模式。如果只是靠符号描述和数据库来实现“强”AI,不如去实现基于事务处理、形象认知、行为模式群的“弱”AI。
学习能力肯定具备,而学习积累到一定“量”级的时候自然会有“自学习”这样一个“学习能力”。人类的学习不象机器,人类是基于观察和经验的。我们看过的小说一个也背不下来。我们人类把记忆最后都理解为行为模式了,包括对某类问题或事物的处理。人的思维不是基于数据量的,AI也不需要数据库。
如果人是由电路构成的。如果人象机器一样存储,那么我给人做个假想——人的学习过程,同时保存了程序、数据、和处理这些数据所需要的电路结构(包括“处理机”、与其他单元间的“调用”和“联系”等),这种学习完成后,就相当于在大大脑里建立了一个专门处理某事务的小“大脑”,以后有同类处理工作,会直接激活这个小大脑与大大脑并行处理。比如打字。这其实也符合现在流行的神经元和神经网络模型。
试着回忆一下从前学过的英语课文,看记住了多少?人脑是非常节省资源的,不会拿脑细胞来记没用的东西。即使是熟知的事物。试试凭印象画出妈妈的脸,看能画出多少细节?能不能和她的照片对应或至少看上去象她?我们到底记住了多少细节?
再比如网络聊天,你观察我打字,你一次同时看到几个字?闭上眼睛,回忆你一直在看的QQ窗口,工具栏上有什么?再想想群友们的名字,刚刚跟你聊天的都有谁?我们记不住。因为不关心。大脑非常节约,你的眼睛,同一时刻也就看到了两三个文字的地方,其他的都是在扫视的过程中形成的联系。我们的眼睛从不一次观察完整幅图像,我们都是“环顾四周”,找出重要的并迅速建立空间模型,包括你与空间和事物的关系。因为人是形象感知的生物,我们处理图形的能力远远超过文字和符号,我们每个人都有自己的空间模型,只不过你可能意识不到。但是你闭上眼,仍然知道周围的大概环境,比如障碍物的大概位置,晚上回家,即使没开灯,也能摸上楼梯,打开家门,打开电灯。这就是空间感。
因此,可以得出这样的猜想:空间模型一定是有的,这是重要的基本的能力之一。它可能是后天形成的,但没形成这种能力之前,也同样没有自主的行为能力。
从实现角度说,如果只是基于运动,观察,和感知,来形成三维映象,基于现在的技术能做的有——1,从两只摄像头的平面图像,拟合出3维物体;2,建立交互式3D引擎,完成对空间的虚拟构建与运动仿真;3,在这个前提下,对观察到的事物,建模,定义,并完成交互运动控制。
我是想把这个过程作为抽象概念认知,甚至整个认知过程的一个前提条件,但并不绝对。声音也差不多,声音可以与具体事物相联系的,和颜色一样,可作为对认知到的事物的一个属性,比如鸟与鸟叫。
而且,不要求一次性建立完备的概念模型。人对一个事物的认识也是渐进的,随着观察的深入,不断修正和补充。但最后记住的不是全部信息,而是关键的、特征的、曾经关注的或经常发生交互的信息。
比如键盘,你一直在用,很熟。试着靠回忆画一下,肯定画不出多少细节,更不用说有几个螺丝这样的特殊性质。因为我们只需要记住它的布局,用法,而其他的,并没有过多关注。
从任何一个单一角度观察,可以形成一个侧面的3维映象与已有经验数据做匹配,得出大概的认识重现(识别),然后随着与其交互的过程,关注更多的方面,完善基础认识。
进一步来说,强调形成三维的认识模型,而不是二维的图像模型,因为事务本身的形态就是三维的。二维的映像可以看作是对三维具像的一个抽像和模拟,并不全面。应该关注实现与实用而不是纯理论和符号系统的AI。如果完成了视觉“观察”并建模,则那么很容易把它概念化。反之,同样一只苹果,完全用文字或符号描述,几乎不可能让AI真正认识它。对人类来说,这个信息的最重要来源是形象认识。
虚拟空间不断动态完成对现实空间的映射,它可以实现运动决策和仿真。比如在没做出“拿”这个动作之前,可以在虚拟空间中“想象”或说“仿真”拿的过程,然后决定怎么拿。只要是在三维空间中能仿真,并且自由度和规则允许的运动,都可以进行实行。
对于3维模型的存储和描述已经有成熟的技术,其他的能力会用更多的处理机制来配合完成,已经有了机制的,可以学习新的认知和方法。不应该把大脑想象成单一形式的生物细织,它有内部有细至的分化,处理每一类事物的组织,都分化成了不同的形式。所以,想以一个基础模型完成整个大脑模拟,是不客观也不现实的。人的很多项“功能”都是后天学习实践中形成的,我们可以找出其中重要的部分模拟它,或只是模仿它。
![3223423.jpg]()
让机器人在三维空间有“我”的概念,和事物的交互关系,不论对强AI还是弱AI在实践中的应用,都是必要的补充和有用的功能。
3维虚拟空间中的模拟“想象”可直接转化为行动。
![2323423432.jpg]()
![2423424.jpg]()
![23434.jpg]()
![242543.jpg]()
![634324.jpg]()
![123424.jpg]()
![42342442.jpg]()
感知——模拟——执行
![423423e4.jpg]()
![xinsrc_5320505091429562238356.jpg]()
![4234424.jpg]()
感知——模拟——交互作用
对环境和自我的“认知”和模拟应该比符号重要,而其中的自主控制,就可称为是某种AI
![130_3521_25ed20d0595a1b6.jpg]()
老万于2011年5月18日
Dreamon-II Labs.
三维环境不用预定义,但至少三维“空间”还是要定义的。如果所谓的强AI中没有空间的概念,没有虚拟的“想象”空间,甚至不会运动,那么,它连最基本的“前,后,左,右”都无法理解。现在在你面前,你认为你看到了空间还是图片?大脑有空间想象力。怎么定义“前”、“后”,与你的空间想象有关,也与你实际的运动经验有关。
我们怎么定义苹果?只是文字描述吗?建立在符号逻辑中的AI没有现实意义。人脑处理的本来就不是符号信息,建立在符号逻辑中的AI没有现实意义。人是靠形象思维的,而概念是对形象思维的抽象。离开了前提直接讨论抽像的符号,能真正“理解”吗?
你心里的苹果是什么?你所“想象”的AI又该怎么认为“苹果”?圆的,红的或绿的,能吃?它会吃么?它知道什么才是圆的?是圆圈还是圆球?无论强AI还是机器认知,想模仿人的话,先从形象思维开始,先从构建3D空间开始。抽象的概念等有了观察的“感性认识”才有意义。
人最先学会的基本都是名词,都是观察的事物和接触到的事物,而且是与自己相关的。第一个动词是“不要”,而后是各种与“名词”表示的具体事物相关的动词。会说“我”这样的代词已经是四五岁以后的事了,这时候才有了自我意识。没有观察,没有形象认知到概念抽象的过程,没有事物与自身关系的感觉,怎么能形成“人类”的意识。
在行动,和认识的经验前提下,三维“感”(也包括立体感),可以从二维图像得到。设想一下,如果从没运动地接触或观察(从多角度接触或观察)过任何事物,那么给你一个单一角度的照片,或只让你从一个角度去看事物及环境能否行成“三维”概念?我认为不能。因为三维是从多角度观察,以及自身的运动与环境的关系,得出的感性体验与认识,你看到事物知道是三维,因为你有过这样的经验。
人类从儿童时期起就是在不断的运动中感知和观察事物。从咬、拿、踩、踢、看、撞等引起的交互感知中来认识环境。这与视觉(或没眼睛靠其他方式)得出的“观察”相结合,产生出“空间感”。
描述一件事物,3维够吗?颜色、温度、硬度、味道、用途、类别,每种你能“类别化”的属性。都可以算作一个维度。从这个意义上讲是无限维。而“三维”只是我们描述空间形态与位置关系的基本手段,远不足以描述“识知”的事物。
脱离形象思维单纯谈认知,至少不符合人类的智能模式,这是关系到实用与实现的问题。AI不一定非照搬人类的模式,但这是最实用的模式。如果只是靠符号描述和数据库来实现“强”AI,不如去实现基于事务处理、形象认知、行为模式群的“弱”AI。
学习能力肯定具备,而学习积累到一定“量”级的时候自然会有“自学习”这样一个“学习能力”。人类的学习不象机器,人类是基于观察和经验的。我们看过的小说一个也背不下来。我们人类把记忆最后都理解为行为模式了,包括对某类问题或事物的处理。人的思维不是基于数据量的,AI也不需要数据库。
如果人是由电路构成的。如果人象机器一样存储,那么我给人做个假想——人的学习过程,同时保存了程序、数据、和处理这些数据所需要的电路结构(包括“处理机”、与其他单元间的“调用”和“联系”等),这种学习完成后,就相当于在大大脑里建立了一个专门处理某事务的小“大脑”,以后有同类处理工作,会直接激活这个小大脑与大大脑并行处理。比如打字。这其实也符合现在流行的神经元和神经网络模型。
试着回忆一下从前学过的英语课文,看记住了多少?人脑是非常节省资源的,不会拿脑细胞来记没用的东西。即使是熟知的事物。试试凭印象画出妈妈的脸,看能画出多少细节?能不能和她的照片对应或至少看上去象她?我们到底记住了多少细节?
再比如网络聊天,你观察我打字,你一次同时看到几个字?闭上眼睛,回忆你一直在看的QQ窗口,工具栏上有什么?再想想群友们的名字,刚刚跟你聊天的都有谁?我们记不住。因为不关心。大脑非常节约,你的眼睛,同一时刻也就看到了两三个文字的地方,其他的都是在扫视的过程中形成的联系。我们的眼睛从不一次观察完整幅图像,我们都是“环顾四周”,找出重要的并迅速建立空间模型,包括你与空间和事物的关系。因为人是形象感知的生物,我们处理图形的能力远远超过文字和符号,我们每个人都有自己的空间模型,只不过你可能意识不到。但是你闭上眼,仍然知道周围的大概环境,比如障碍物的大概位置,晚上回家,即使没开灯,也能摸上楼梯,打开家门,打开电灯。这就是空间感。
因此,可以得出这样的猜想:空间模型一定是有的,这是重要的基本的能力之一。它可能是后天形成的,但没形成这种能力之前,也同样没有自主的行为能力。
从实现角度说,如果只是基于运动,观察,和感知,来形成三维映象,基于现在的技术能做的有——1,从两只摄像头的平面图像,拟合出3维物体;2,建立交互式3D引擎,完成对空间的虚拟构建与运动仿真;3,在这个前提下,对观察到的事物,建模,定义,并完成交互运动控制。
我是想把这个过程作为抽象概念认知,甚至整个认知过程的一个前提条件,但并不绝对。声音也差不多,声音可以与具体事物相联系的,和颜色一样,可作为对认知到的事物的一个属性,比如鸟与鸟叫。
而且,不要求一次性建立完备的概念模型。人对一个事物的认识也是渐进的,随着观察的深入,不断修正和补充。但最后记住的不是全部信息,而是关键的、特征的、曾经关注的或经常发生交互的信息。
比如键盘,你一直在用,很熟。试着靠回忆画一下,肯定画不出多少细节,更不用说有几个螺丝这样的特殊性质。因为我们只需要记住它的布局,用法,而其他的,并没有过多关注。
从任何一个单一角度观察,可以形成一个侧面的3维映象与已有经验数据做匹配,得出大概的认识重现(识别),然后随着与其交互的过程,关注更多的方面,完善基础认识。
进一步来说,强调形成三维的认识模型,而不是二维的图像模型,因为事务本身的形态就是三维的。二维的映像可以看作是对三维具像的一个抽像和模拟,并不全面。应该关注实现与实用而不是纯理论和符号系统的AI。如果完成了视觉“观察”并建模,则那么很容易把它概念化。反之,同样一只苹果,完全用文字或符号描述,几乎不可能让AI真正认识它。对人类来说,这个信息的最重要来源是形象认识。
虚拟空间不断动态完成对现实空间的映射,它可以实现运动决策和仿真。比如在没做出“拿”这个动作之前,可以在虚拟空间中“想象”或说“仿真”拿的过程,然后决定怎么拿。只要是在三维空间中能仿真,并且自由度和规则允许的运动,都可以进行实行。
对于3维模型的存储和描述已经有成熟的技术,其他的能力会用更多的处理机制来配合完成,已经有了机制的,可以学习新的认知和方法。不应该把大脑想象成单一形式的生物细织,它有内部有细至的分化,处理每一类事物的组织,都分化成了不同的形式。所以,想以一个基础模型完成整个大脑模拟,是不客观也不现实的。人的很多项“功能”都是后天学习实践中形成的,我们可以找出其中重要的部分模拟它,或只是模仿它。

让机器人在三维空间有“我”的概念,和事物的交互关系,不论对强AI还是弱AI在实践中的应用,都是必要的补充和有用的功能。
3维虚拟空间中的模拟“想象”可直接转化为行动。







感知——模拟——执行



感知——模拟——交互作用
对环境和自我的“认知”和模拟应该比符号重要,而其中的自主控制,就可称为是某种AI

老万于2011年5月18日
Dreamon-II Labs.

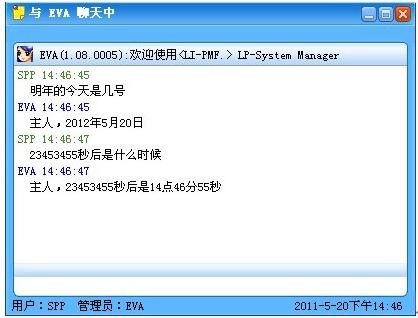
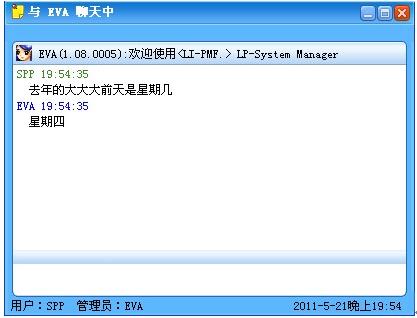
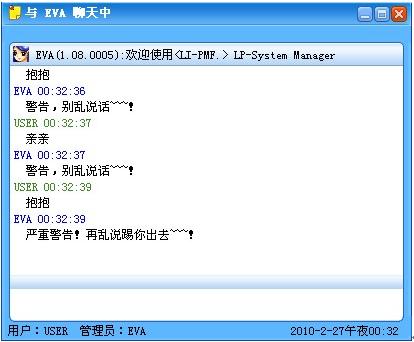


















200字以内,仅用于支线交流,主线讨论请采用回复功能。